十大算法
递归算法
能够用递归解决的问题需要满足三个条件:
- 原问题可以转换为一个或多个子问题来求解,而这些子问题的求解方法和原问题完全相同,只是规模不同;
- 递归调用次数必须是有限的;
- 必须有结束递归的条件(递归出口)来终止递归。
设计递归算法模式
- 先求解问题的递归模型。
- 在设计递归算法的时候,如果纠结递归树的每一个阶段的话,就会极为复杂。因此,只考虑递归树中的第一层和第二层之间的关系即可,即“大问题” 和 “小问题” 的关系,其他关系类似。
- 求解问题的递归模型:
- 对原问题
f(n)进行分析,假设出合理的小问题f(n-1); - 假设小问题 f(n-1) 是可解的,在此基础上确定大问题 f(n) 的解,即给出 f(n) 与 f(n-1) 之间的关系,也就是确定了递归体。(与数学归纳法中确定
i=n-1时成立,再求证i=n时等式成立的过程相似)。还要明确需要返回什么信息给上一层递归调用。 - 确定一个特定情况(如 f(0) 或 f(1))的解,由此作为递归出口。(与数学归纳法中求证
i=0或i=1时等式成立相似)
- 对原问题
例子:求数组中最小值:
1 | /** |
分治算法
分治法是一种很重要的算法。字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
分治法适用的情况
分治算法所能解决的问题一般具有以下几个特征:
1) 该问题的规模缩小到一定的程度就可以容易地解决
2) 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
3) 利用该问题分解出的子问题的解可以合并为该问题的解;
如果不具备这一条特征, 那么可以考虑使用贪心算法或者动态规划算法
4) 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
如果各子问题是不独立的则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然可用分治法,但一般用动态规划法较好。
分治法的基本步骤
分治法在每一层递归上都有三个步骤:
- (1)分解,将要解决的问题划分成若干规模较小的同类问题;
- (2)求解,当子问题划分得足够小时,用较简单的方法解决;
- (3)合并,按原问题的要求,将子问题的解逐层合并构成原问题的解。
分治算法的设计模式:
1 | Divide_and_Conquer(P){ |
案例:
求数组的和
1
2
3
4
5
6private static int getSum(int[] arr, int low, int high) {
if (low >= high) return arr[high];// “治” 直接求解
int mid = (low + high) / 2;// “分” 分解成两个子问题
// “合” 自底向上求子数组l和r的和
return getSum(arr, low, mid) + getSum(arr, mid + 1, high);
}
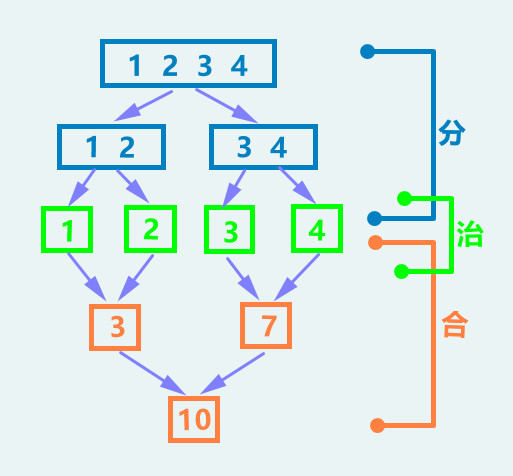
分治 - 求逆序对数目
如,
{3, 1, 2, 4}中逆序对有<3,1> <3,2>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40static int getReverseCount(int[] arr, int low, int high) {
//治
if (low >= high) return 0;
//分 成子问题,子问题解有三个
//1. 左边部分的解
//2. 右边部分的解
//3. 左右两部分合起来的解
int mid = (low + high) / 2;
int lC = getReverseCount(arr, low, mid);
int rC = getReverseCount(arr, mid + 1, high);
int mergeC = merge(arr, low, mid, high);
//合并子问题的解(3个)
return lC + rC + mergeC;
}
private static int merge(int[] arr, int low, int mid, int high) {
//将左右两部分的限定区间内的值拿出来(这样不会影响整体)求左右两部分合起来的解-> 把中间部分拿出来排好序在放回去
int[] tmp = Arrays.copyOfRange(arr, low, high + 1);
int nMid = mid - low;
int nHigh = tmp.length - 1;
int num = 0;//逆序数
//开始求两部分合起来的解(仅仅!! 把中间那部分拿出来进行排序后,放回到原数组arr中)
int index = low;
int p1 = 0;
int p2 = nMid + 1;
while (p1 <= nMid && p2 <= nHigh) {
// 比较左右两部分的元素,哪个小,把那个元素填入原数组index位置中
if (tmp[p1] > tmp[p2]) {
num++;
System.out.println(tmp[p1] + " " + tmp[p2]);
arr[index++] = tmp[p2++];
} else {
arr[index++] = tmp[p1++];
}
}
//把剩余的元素填入arr相应位置
while (p1 <= nMid) arr[index++] = tmp[p1++];
while (p2 <= nHigh) arr[index++] = tmp[p2++];
return num;
}
动态规划
动态规划过程是:每次决策依赖于当前状态,又随即引起状态的转移。是一种分阶段求解决策问题的数学思想。总结起来就是一句话,大事化小,小事化了。
基本思想与分治法类似,也是将待求解的问题分解为若干个子问题(阶段),按顺序求解子阶段,前一子问题的解,为后一子问题的求解提供了有用的信息。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他局部解。依次解决各子问题,最后一个子问题就是初始问题的解。
通用递推式:
$$
f(n,m)=max{f(n-1,m), f(n-1,m-w[n])+P(n,m)}
$$
优化:
由于动态规划解决的问题多数有重叠子问题这个特点,为减少重复计算,对每一个子问题只解一次,将其不同阶段的不同状态保存在一个二维数组中。
分治法最大的差别:
适合于用动态规划法求解的问题,经分解后得到的子问题往往不是互相独立的(即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解)。
适用的情况
能采用动态规划求解的问题的一般要具有3个性质:
- 最优化原理:如果问题的最优解所包含的子问题的解也是最优的,就称该问题具有最优子结构,即满足最优化原理。
- 无后效性:即某阶段状态一旦确定,就不受这个状态以后决策的影响。也就是说,某状态以后的过程不会影响以前的状态,只与当前状态有关。
- 有重叠子问题:即子问题之间是不独立的,一个子问题在下一阶段决策中可能被多次使用到。(该性质并不是动态规划适用的必要条件,但是如果没有这条性质,动态规划算法同其他算法相比就不具备优势)
求解的基本步骤
初始状态→│决策1│→│决策2│→…→│决策n│→结束状态
- 划分阶段:按照问题的时间或空间特征,把问题分为若干个阶段。在划分阶段时,注意划分后的阶段一定要是有序的或者是可排序的,否则问题就无法求解。
- 确定状态和状态变量->(递归的定义最优解。):将问题发展到各个阶段时所处于的各种客观情况用不同的状态表示出来。当然,状态的选择要满足无后效性。
- 确定决策并写出状态转移方程:因为决策和状态转移有着天然的联系,状态转移就是根据上一阶段的状态和决策来导出本阶段的状态。所以如果确定了决策,状态转移方程也就可写出。但事实上常常是反过来做,根据相邻两个阶段的状态之间的关系来确定决策方法和状态转移方程。
- 寻找边界条件:给出的状态转移方程是一个递推式,需要一个递推的终止条件或边界条件。
动态规划案例
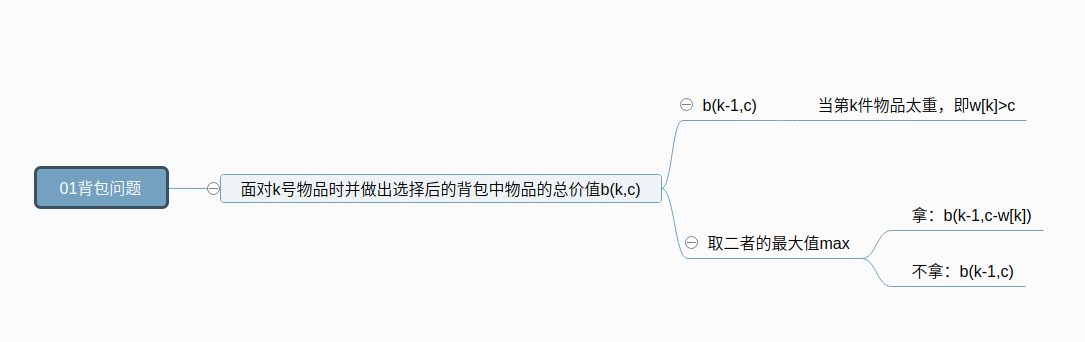
0, 1背包问题
两种情况来分析, 要拿的东西能不能装进背包,能装进去的话,要不要那它(看价值)
- 如果第k件物品的重量w[k]比此时的背包的剩余重量c大了,那我肯定是拿不动了,即
w[k]>c。所以此时包中物品的价值就是我拿的前一个物品之后包中的价值,即b(k,c)=b(k-1,c).包中剩余空间不变,还是c。 - 那么第二种情况,如果我拿得动第k件物品,即第k件物品的重量
w[k]<c,面对k号物品,无外乎两种选择,拿或者不拿,这时我就要根据拿走之后产生的效益进行决策了:- 不拿k号物品,那么此时包中物品的总价值
b(k,c)=b(k-1,c),和第一种拿不动k号物品的一样。 - 拿走k号物品,那么此时包中物品的总价值
b(k,c)=b(k-1,c-w[k])+v[k]拿了第k件物品后,那我的包中的价值肯定就是原先的价值再加上第k件物品的价值,而且拿了之后包中的剩余容量就为c-w[k]了。 总结一下,就是如下的公式了:b(k,c)=max{b(k-1,c),b(k-1,c-w[k])+v[k]}
- 不拿k号物品,那么此时包中物品的总价值
1 | class Main { |
1 | //递归方式 |
贪心算法
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。
必须注意的是,贪心算法不是对所有问题都能得到整体最优解,采用的贪心策略一定要仔细分析其是否满足无后效性。即某个状态以后的过程不会影响以前的状态
贪心算法的基本思路:
1.建立数学模型来描述问题。
2.把求解的问题分成若干个子问题。
3.对每一子问题求解,得到子问题的局部最优解。
4.把子问题的解局部最优解合成原来解问题的一个解。
贪心算法适用的问题
贪心策略适用的前提是:局部最优策略能导致产生全局最优解。
实际上,贪心算法适用的情况很少。一般,对一个问题分析是否适用于贪心算法,可以先选择该问题下的几个实际数据进行分析,就可做出判断。
贪心算法的实现框架
- 从问题的某一初始解出发;
- while (能朝给定总目标前进一步)
- {
- 利用可行的决策,求出可行解的一个解元素;
- }
- 由所有解元素组合成问题的一个可行解;
案例
物品装载问题:
最优装载问题,给出n个物体,第i个物体重量为wi。选择尽量多的物体,使得总重量不超过C。经过前面的学习很容易想到贪心策略,那就是每次选重量最轻的物体,那么物体数就最多。
1 | /** |
回溯算法
回溯法是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
许多复杂的,规模较大的问题都可以使用回溯法,有“通用解题方法”的美称。
回溯算法设计模式:
(1)针对所给问题,确定问题的解空间:
首先应明确定义问题的解空间,问题的解空间应至少包含问题的一个(最优)解。
(2)确定结点的扩展搜索规则
(3)以深度优先方式搜索解空间,并在搜索过程中用剪枝函数避免无效搜索。
案例
八皇后问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20void back_tracking(int row=0) //算法函数,从第0行开始遍历
{
if (row==n)
t ++; //判断若遍历完成,就进行计数
for (int col=0;col<n;col++) //遍历棋盘每一列
{
queen[row] = col; //将皇后的位置记录在数组
if (is_ok(row)) //判断皇后的位置是否有冲突
back_tracking(row+1); //递归,计算下一个皇后的位置
}
}
bool is_ok(int row){ //判断设置的皇后是否在同一行,同一列,或者同一斜线上
for (int j=0;j<row;j++)
{
if (queen[row]==queen[j]||row-queen[row]==j-queen[j]||row+queen[row]==j+queen[j])
return false;
}
return true;
}
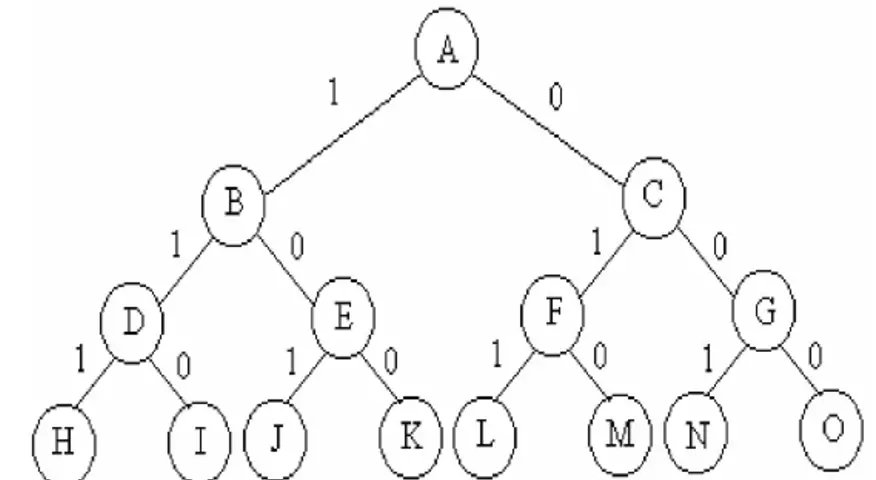
01背包问题
用回溯法解问题时,应明确定义问题的解空间。问题的解空间至少包含问题的一个(最优)解。对于 n=3 时的 0/1 背包问题,可用一棵完全二叉树表示解空间
求解步骤
1)针对所给问题,定义问题的解空间;
2)确定易于搜索的解空间结构;
3)以深度优先方式搜索解空间,并在搜索过程中用剪枝函数避免无效搜索。
常用的剪枝函数:用约束函数在扩展结点处剪去不满足约束的子树;用限界函数剪去得不到最优解的子树。
回溯法对解空间做深度优先搜索时,有递归回溯和迭代回溯(非递归)两种方法,但一般情况下用递归方法实现回溯法。
算法描述
解 0/1 背包问题的回溯法在搜索解空间树时,只要其左儿子结点是一个可行结点,搜索就进入其左子树。当右子树中有可能包含最优解时才进入右子树搜索。否则将右子树剪去。
1 | void dfs(int i,int cv,int cw) |
主函数部分
1 | int main() |
分支限界法
类似于回溯法,也是一种在问题的解空间树T上搜索问题解的算法。但在一般情况下,分支限界法与回溯法的求解目标不同。回溯法的求解目标是找出T中满足约束条件的所有解,而分支限界法的求解目标则是找出满足约束条件的一个解,或是在满足约束条件的解中找出使某一目标函数值达到极大或极小的解,即在某种意义下的最优解。
所谓“分支”就是采用广度优先的策略,依次搜索E-结点的所有分支,也就是所有相邻结点,抛弃不满足约束条件的结点,其余结点加入活结点表。然后从表中选择一个结点作为下一个E-结点,继续搜索。
选择下一个E-结点的方式不同,则会有几种不同的分支搜索方式。
1)FIFO搜索
2)LIFO搜索
3)优先队列式搜索